Name
pg_bulkload -- it provides high-speed data loading capability to PostgreSQL users.
Synopsis
pg_bulkload [ OPTIONS ] [ controlfile ]
Description
IMPORTANT NOTE: Under streaming replication environment, pg_bulkload does not work properly. See here for details.
pg_bulkload is designed to load huge amount of data to a database. You can choose whether database constraints are checked and how many errors are ignored during the loading. For example, you can skip integrity checks for performance when you copy data from another database to PostgreSQL. On the other hand, you can enable constraint checks when loading unclean data.
The original goal of pg_bulkload was an faster alternative of COPY command in PostgreSQL,
but version 3.0 or later has some ETL features like input data validation and data transformation with filter functions.
In version 3.1, pg_bulkload can convert the load data into the binary file which can be used as an input file of pg_bulkload. If you check whether the load data is valid when converting it into the binary file, you can skip the check when loading it from the binary file to a table. Which would reduce the load time itself. Also in version 3.1, parallel loading works more effectively than before.
There are some bugs in old version of 3.1. Please check Release notes, and use newer versions.
Examples
pg_bulkload provides two programs.
postgresql script
This is a wrapper command for pg_ctl, which starts and stops PostgreSQL
server. postgresql script invokes pg_ctl internally. postgresql script
provides very important pg_bulkload functionality i.e. recovery. To improve
performance, pg_bulkload bypasses some of PostgreSQL's internal functionality
such as WAL. Therefore, pg_bulkload needs to provide separate recovery
procedure before usual PostgreSQL's recovery is performed. postgresql script
provides this feature.
You must see below "Restrictions", especially if you use pg_bulkload in DIRECT or PARALLEL load modes. It requires special database recovery processes. Notice that DIRECT mode is the default settings.
pg_bulkload
This program is used to load the data. Internally, it invokes PostgreSQL's user-defined function called pg_bulkload() and perform the loading. pg_bulkload() function will be installed during pg_bulkload installation.
You can use pg_bulklad by the following three steps:
- Edit control file "sample_csv.ctl" or "sample_bin.ctl" that includes settigs for data loading. You can specify table name, absolute path for input file, description of the input file, and so on.
- Assume there is a directory
$PGDATA/pg_bulkload, in that load status files are created. - Execute command with a control file as argument. Relative path is available for the argument.
$ pg_bulkload sample_csv.ctl NOTICE: BULK LOAD START NOTICE: BULK LOAD END 0 Rows skipped. 8 Rows successfully loaded. 0 Rows not loaded due to parse errors. 0 Rows not loaded due to duplicate errors. 0 Rows replaced with new rows.
Options
pg_bulkload has the following command line options:
Load Options
Options to load data.
-
-i INPUT
--input=INPUT
--infile=INPUT - Source to load data from. Same as "INPUT" in control files.
-
-O OUTPUT
--output=OUTPUT - Destination to load data to. Same as "OUTPUT" in control files.
-
-l LOGFILE
--logfile=LOGFILE - A path to write the result log. Same as "LOGFILE" in control files.
-
-P PARSE_BADFILE
--parse-badfile=PARSE_BADFILE - A path to write bad records that cannot be parsed correctly. Same as "PARSE_BADFILE" in control files.
-
-u DUPLICATE_BADFILE
--duplicate-badfile=DUPLICATE_BADFILE - A path to write bad records that conflict with unique constraints during index rebuild. Same as "DUPLICATE_BADFILE" in control files.
-
-o "key=val"
--option="key=val" - Any options available in the control file. You can pass multiple options.
Connection Options
Options to connect to servers.
-
-d dbname
--dbname dbname - Specifies the name of the database to be connected. If this is not specified, the database name is read from the environment variable PGDATABASE. If that is not set, the user name specified for the connection is used.
- -h host
--host host - Specifies the host name of the machine on which the server is running. If the value begins with a slash, it is used as the directory for the Unix domain socket.
- -p port
--port port - Specifies the TCP port or local Unix domain socket file extension on which the server is listening for connections.
- -U username
--username username - User name to connect as.
- -W
--password - Force pg_bulkload to prompt for a password before connecting to a database.
- This option is never essential, since pg_bulkload will automatically prompt for a password if the server demands password authentication. However, vacuumdb will waste a connection attempt finding out that the server wants a password. In some cases it is worth typing -W to avoid the extra connection attempt.
Generic Options
- -e
--echo - Echo commands sent to server.
- -E
--elevel - Choose the output message level from DEBUG, INFO, NOTICE, WARNING, ERROR, LOG, FATAL, and PANIC. The default is INFO.
- --help
- Show usage of the program.
- --version
- Show the version number of the program.
Control Files
You can specify the following load options. Control files can be specifed with an absolute path or a relative path. If you specify it by a relative path, it will be relative to the current working directory executing pg_bulkload command. If you don't specify a control file, you should pass required options through command line arguments for pg_bulkload.
Following parameters are available in control files. Characters after "#" are ignored as comments in each line.
Common
- TYPE = CSV | BINARY | FIXED | FUNCTION
-
The type of input data.
The default is CSV.
- CSV : load from a text file in CSV format
- BINARY | FIXED : load from a fixed binary file
- FUNCTION : load from a result set from a function.
If you use it, INPUT must be an expression to call a function.
- INPUT | INFILE = path | stdin | [ schemaname. ] function_name (argvalue, ...)
-
Source to load data from. Always required.
The value is treated as following depending on the TYPE option:
- A file in the server: This is a file path in server. If it is a relative path, it will be relative from the control file when specified in the control file, or will be relative from current working directory when specified in command line arguments. The user of PostgreSQL server must have read permission to the file. It is available only when "TYPE=CSV" or "TYPE=BINARY".
- Standard input to pg_bulkload command:
"INPUT=stdin" means pg_bulkload will read data from the standard input of pg_bulkload client program through network.
You should use this form when the input file and database is in different servers.
It is available only when "TYPE=CSV" or "TYPE=BINARY".
For example:
$ pg_bulkload csv_load.ctl < DATA.csv
- A SQL function:
Specify a SQL function with arguments that returns set of input data.
It is available only when "TYPE=FUNCTION".
You can use not only build-in functions but also any user-defined functions.
The defined functions should return the type as SETOF sometype, or as RETURNS TABLE(columns).
Note that you specify attributes types if you use sometype. Because there is a case that
assignment cast to cstring type which pg_bulkload uses internally, doesn't be permitted.
Note that you might need to develop those function with C language instead of PL/pgSQL
because the function must use SFRM_ValuePerCall mode for streaming loading.
Here is an example of user-defined function.
$ CREATE TYPE sample_type AS (sum integer, name char(10)); $ CREATE FUNCTION sample_function() RETURNS SETOF sample_type AS $$ SELECT id1 + id2, upper(name) FROM INPUT_TABLE $$ LANGUAGE SQL;Here is an example of a control file.
TABLE = sample_table TYPE = FUNCTION WRITER = DIRECT INPUT = sample_function() # if to use the user-defined function #INPUT = generate_series(1, 1000) # if to use the build-in function, which generate sequential numbers from 1 to 1000
- WRITER | LOADER = DIRECT | BUFFERED | BINARY | PARALLEL
-
The method to load data. The default is DIRECT.
- DIRECT : Load data directly to table. Bypass the shared buffers and skip WAL logging, but need the own recovery procedure. This is the default, and original older version's mode.
- BUFFERED : Load data to table via shared buffers. Use shared buffers, write WALs, and use the original PostgreSQL WAL recovery.
- BINARY : Convert data into the binary file which can be used as an input file to load from. Create a sample of the control file necessary to load the output binary file. This sample file is created in the same directory as the binary file, and its name is <binary-file-name>.ctl.
- PARALLEL : Same as "WRITER=DIRECT" and "MULTI_PROCESS=YES". If PARALLEL is specified, MULTI_PROCESS is ignored. If password authentication is configured to the database to load, you have to set up the password file. See Restrictions for details.
- OUTPUT | TABLE = { [ schema_name. ] table_name | outfile }
-
Destination to load data to. Always required.
The value is treated as following depending on the WRITER (or LOADER) option:
- A table to load to: Specify the table to load to. If schema_name is omitted, the first matching table in the search_path is used. You can load data to a table only if WRITER is DIRECT, BUFFERED or PARALLEL.
- A file in the server: Specify the path of the output file in the server. If it's a relative path, it will be interpreted in the same way as INPUT option. The OS user running PostgreSQL must have write permission to the parent directory of the specified file. You can load (convert) data to a file only if WRITER is BINARY.
- SKIP | OFFSET = n
- The number of skip input rows. The default is 0. You must not specify both "TYPE=FUNCTION" and SKIP at the same time.
- LIMIT | LOAD = n
- The number of rows to load. The default is INFINITE, i.e., all of data will be loaded. This option is available even if you use TYPE=FUNCTION.
- ENCODING = encoding
- Specify the encoding of the input data. Check whether the specified encoding is valid, and convert the input data to the database encoding if needed. By default, the encoding of the input data is neither verified nor converted. If you can be sure that the input data is encoded in the database encoding, you can reduce the load time by not specifying this option, and by skipping encoding verification and conversion. Note that client_encoding is used as the encoding of the input data by default only if INPUT is stdin. You must not specify both "TYPE=FUNCTION" and ENCODING at the same time.
- See Built-in Conversions for valid encoding names. Here are option values and actual behaviors:
-
DB encoding SQL_ASCII non-SQL_ASCII ENCODING not specified neither checked nor converted neither checked nor converted SQL_ASCII neither checked nor converted only checked non-SQL_ASCII, same as DB only checked only checked non-SQL_ASCII, different from DB only checked checked and converted - FILTER = [ schema_name. ] function_name [ (argtype, ... ) ]
- Specify the filter function to convert each row in the input file. You can omit definitions of argtype as long as the function name is unique in the database. If not specified, the input data are directly parsed as the load-target table. See also How to write FILTER functions to make FILTER functions.
- You must not specify both "TYPE=FUNCTION" and FILTER at the same time. Also, FORCE_NOT_NULL in CSV option cannot be used with FILTER option.
- CHECK_CONSTRAINTS = YES | NO
- Specify whether CHECK constraints are checked during the loading. The default is NO. You must not specify both "WRITER=BINARY" and CHECK_CONSTRAINTS at the same time.
- PARSE_ERRORS = n
- The number of ingored tuples that throw errors during parsing, encoding checks, encoding conversion, FILTER function, CHECK constraint checks, NOT NULL checks, or data type conversion. Invalid input tuples are not loaded and recorded in the PARSE BADFILE. The default is 0. If there are equal or more parse errors than the value, already loaded data is committed and the remaining tuples are not loaded. 0 means to allow no errors, and -1 and INFINITE mean to ignore all errors.
- DUPLICATE_ERRORS = n
- The number of ingored tuples that violate unique constraints. Conflicted tuples are removed from the table and recorded in the DUPLICATE BADFILE. The default is 0. If there are equal or more unique violations than the value, the whole load is rollbacked. 0 means to allow no violations, and -1 and INFINITE mean to ignore all violations. You must not specify both "WRITER=BINARY" and DUPLICATE_ERRORS at the same time.
- ON_DUPLICATE_KEEP = NEW | OLD
- Specify how to handle tuples that violate unique constraints.
The removed tuples are recorded in the BAD file.
The default is NEW.
You also need to set DUPLICATE_ERRORS to more than 0 if you enable the option.
You must not specify both "WRITER=BINARY" and ON_DUPLICATE_KEEP at the same time.
- NEW : Keep tuples in the input data, and remove corresponding existing tuples. When both violated tuples are in the data, keep the latter one.
- OLD : Keep existing tuples and remove tuples in the input data.
- LOGFILE = path
- A path to write the result log. If specified by a relative path, it is treated as same as INPUT. The default is $PGDATA/pg_bulkload/<timestamp>_<dbname>_<schema>_<table>.log.
- PARSE_BADFILE = path
- A path to the BAD file logging invalid records which caused an error during parsing, encoding checks, encoding conversion, FILTER function, CHECK constraint checks, NOT NULL checks, or data type conversion. The format of the file is same as the input source file. If specified by a relative path, it is treated as same as INPUT. The default is $PGDATA/pg_bulkload/<timestamp>_<dbname>_<schema>_<table>.bad.<extension-of-infile>.
- DUPLICATE_BADFILE = path
- A path to write bad records that conflict with unique constraints during index rebuild. The format of the file is always CSV. If specified by a relative path, it is treated as same as INPUT. The default is $PGDATA/pg_bulkload/<timestamp>_<dbname>_<schema>_<table>.dup.csv. You must not specify both "WRITER=BINARY" and DUPLICATE_BADFILE at the same time.
- TRUNCATE = YES | NO
- If YES, delete all rows from the target table with TRUNCATE command. If NO, do nothing. The default is NO. You must not specify both "WRITER=BINARY" and TRUNCATE at the same time.
- VERBOSE = YES | NO
- If YES, write bad tuples also in server log. If NO, don't write them in serverlog. The default is NO.
- MULTI_PROCESS = YES | NO
- If YES, we do data reading, parsing and writing in parallel by using multiple threads. If NO, we use only single thread for them instead of doing parallel processing. The default is NO. If WRITER is PARALLEL, MULTI_PROCESS is ignored. If password authentication is configured to the database to load, you have to set up the password file. See Restrictions for details. Please make sure when enabling MULTI_PROCESS that no other PostgreSQL backend process is trying to modify the schema of the table, because it may cause the schema of the table as seen by the reader and the writer processes to differ and cause problems.
CSV input format
- DELIMITER = delimiter_character
-
The single ASCII character that separates columns within each row (line) of the file.
The default is comma.
When you load a tab-separated format file (TSV), you can set DELIMITER to a tab character.
Then, you need to double quote the tab:
DELIMITER=" " # a double-quoted tab
You can also specify DELIMITER as a command-line -o option with$'\t'syntax.$ pg_bulkload tsv.ctl -o $'DELIMITER=\t'
- QUOTE = quote_character
- Specifies the ASCII quotation character. The default is double-quotation.
- ESCAPE = escape_character
- Specifies the ASCII character that should appear before a QUOTE data character value. The default is double-quotation.
- NULL = null_string
- The string that represents a null value. The default is a empty value with no quotes.
- FORCE_NOT_NULL = column
- Process each specified column as though it were not a NULL value. Multiple columns are available as needed. FILTER cannot be used together with this option.
Binary input format
- COL = type [ (size) ] [ NULLIF { 'null_string' | null_hex } ]
-
Column definitions of input file from left to right.
The definitions consists of type name, offset, and length in bytes.
CHAR and VARCHAR means input data is a text.
Otherwise, it is a binary data.
If binary, endian must match between server and data file.
- CHAR | CHARACTER : a string trimmed trailing spaces. The length is always required.
- VARCHAR | CHARACTER VARYING : a string keeping trailing spaces. The length is always required.
- SMALLINT | SHOFT : signed integer in 2 bytes.
- INTEGER | INT : signed integer in 2 or 4 or 8 bytes. The default is 4.
- BIGINT | LONG : signed integer in 8 bytes.
- UNSIGNED SMALLINT | SHORT : unsigned integer in 2 bytes.
- UNSIGNED INTEGER | INT : unsigned integer in 2 or 4 bytes. The default is 4.
- FLOAT | REAL : floating point number in 4 or 8 bytes. The default is 4.
- DOUBLE : floating point number in 8 bytes.
- TYPE : TYPE with default length follows.
- TYPE(L) : TYPE with L bytes follows.
- TYPE(S+L) : L bytes, offset S bytes from the beginning of the line
- TYPE(S:E) : start at S bytes and end at E bytes.
- NULLIF 'null_string' : Specify the string expressing NULL when the type is CHAR or VARCHAR. The length of the string must be the same as that of the type.
- NULLIF null_hex : Specify the hex value expressing NULL when the type is other than CHAR and VARCHAR. The length of the hex value must be the same as that of the type.
- PRESERVE_BLANKS = YES | NO
- YES regards following "COL N" as "COL CHAR(N)" and NO as "COL VARCHAR(N)". Default is NO.
- STRIDE = n
- Length of one row. Use if you want to truncate the end of row. The default is whole of the row, which means the total of COLs.
Binary output format
- OUT_COL = type [ (size) ] [ NULLIF { 'null_string' | null_hex } ]
-
Column definitions of output file from left to right.
The definitions consists of type name, offset, and length in bytes.
CHAR and VARCHAR means input data is a text.
Otherwise, it is a binary data.
If binary, endian must match between server and data file.
- CHAR | CHARACTER : fixed-length string. The length must be specified. If the string to be stored is shorter than the declared length, values will be space-padded. "COL=CHAR(size)" will be output in the sample of control file.
- VARCHAR | CHARACTER VARYING : fixed-length string. The length must be specified. If the string to be stored is shorter than the declared length, values will be space-padded. "COL=VARCHAR(size)" will be output in the sample of control file.
- SMALLINT | SHOFT : signed integer in 2 bytes.
- INTEGER | INT : signed integer in 2 or 4 or 8 bytes. The default is 4.
- BIGINT | LONG : signed integer in 8 bytes.
- UNSIGNED SMALLINT | SHORT : unsigned integer in 2 bytes.
- UNSIGNED INTEGER | INT : unsigned integer in 2 or 4 bytes. The default is 4.
- FLOAT | REAL : floating point number in 4 or 8 bytes. The default is 4.
- DOUBLE : floating point number in 8 bytes.
- NULLIF 'null_string' : Specify the string expressing NULL when the type is CHAR or VARCHAR. The length of the string must be the same as that of the type.
- NULLIF null_hex : Specify the hex value expressing NULL when the type is other than CHAR and VARCHAR. The length of the hex value must be the same as that of the type.
Environment
The followin envionment variables affect pg_bulkload.
-
PGDATABASE
PGHOST
PGPORT
PGUSER - Default connection parameters
This utility, like most other PostgreSQL utilities, also uses the environment variables supported by libpq (see Environment Variables).
Restrictions
Support for pluggable table access methods in PostgreSQL 12
pg_bulkload currently only supports loading data into tables of access method named "heap". Note that it is the method that core PostgreSQL has always used, but has been revised in PostgreSQL 12 to go through the new pluggable table access API.
Exit code of pg_bulkload
pg_bulkload returns 0 when succesfully loaded. It also returns 3 with a WARNING message when there are some parse errors or duplicate errors even if loading itself was finished. Note that skipped rows and replaced rows (with ON_DUPLICATE_KEEP = NEW) are not considered as an error; the exit code will be 0.
When there is a non-continuable error, the loader raises an ERROR message. The return code will be often 1 because many errors occur in the database server during loading data. The following table shows the codes that pg_bulkload can return.
| Return code | Description |
|---|---|
| 0 | Success |
| 1 | Error occurred during running SQL in PostgreSQL |
| 2 | Failed to connect to PostgreSQL |
| 3 | Success, but some data could not be loaded |
On direct loading
If you use direct load mode (WRITER=DIRECT or PARALLEL), you have to be aware below:
PostgreSQL startup sequence
When pg_bulkload is crashed and some .loadstatus files are remained in $PGDATA/pg_bulkload, database must be recovered by pg_bulkload own recovery with "pg_bulkoad -r" command before you invoke pg_ctl start.
You must start and stop PostgreSQL using postgresql script, which invokes "pg_bulkload -r" and "pg_ctl start" correctly. We recommend not to use pg_ctl directly.
If you use pg_bulkload in Windows operating system, postgresql script is not included in a pg_bulkload package. So you have to invoke "pg_bulkload -r" manually.
PITR/Replication
Because of bypassing WAL, archive recovery by PITR is not available. This does not mean that it can be done PITR without loaded tables data. If you would like to use PITR, take a full backup of the database after load via pg_bulkload. If you are using streaming replication, you need to re-create your standby based on the backup set which is taken after pg_bulkload.
Load status file in $PGDATA/pg_bulkload
You must not remove the load status file (*.loadstatus) found in
$PGDATA/pg_bulkload directory.
This file is needed in pg_bulkload crash recovery.
Do not use kill -9
Do not terminate pg_bulkload command using "kill -9" as much as possible. If you did this, you
must invoke postgresql script to perform pg_bulkload recovery and restart
PostgreSQL to continue.
Authentication can fail when MULTI_PROCESS=YES
When MULTI_PROCESS=YES and password is required to connect from localhost
to the database to load, the authentication will fail even if you enter
the password correctly in the prompt. To avoid this, configure either of the followings.
- Use "trust" method to authenticate the connection from localhost
In UNIX environment, the connection from localhost uses UNIX-domain socket, and in Windows, it uses TCP/IP loopback address. In UNIX, add the following line into pg_hba.conf.
# TYPE DATABASE USER CIDR-ADDRESS METHOD [for UNIX] local all foo trust
In Windows, add the following line into pg_hba.conf.
# TYPE DATABASE USER CIDR-ADDRESS METHOD [for Windows] host all foo 127.0.0.1/32 trust
- Specify the password in .pgpass file
If you don't want to use "trust" method for security reasons, use "md5" or "password" as an authentication method and specify the password in .pgpass file. Note that the .pgpass file must be in the home directory of the OS user (typically "postgres" user) who ran PostgreSQL server. For example, if pg_bulkload connects to the server that is running on port 5432 as the DB user "foo" whose password is "foopass", the administrator can add the following line to the .pgpass file:localhost:5432:*:foo:foopass
- Don't use "WRITER=PARALLE"
Use the loading method other than "WRITER=PARALLEL".
Database Constraints
Only unique constraint and not-NULL constraint are enforced during data load in default. You can to set "CHECK_CONSTRAINTS=YES" to check CHECK constraints. Foreign key constraints cannot be checked. It is user's responsibility to provide valid data set.
Details
Internal
Here is an internal structure in pg_bulkload.
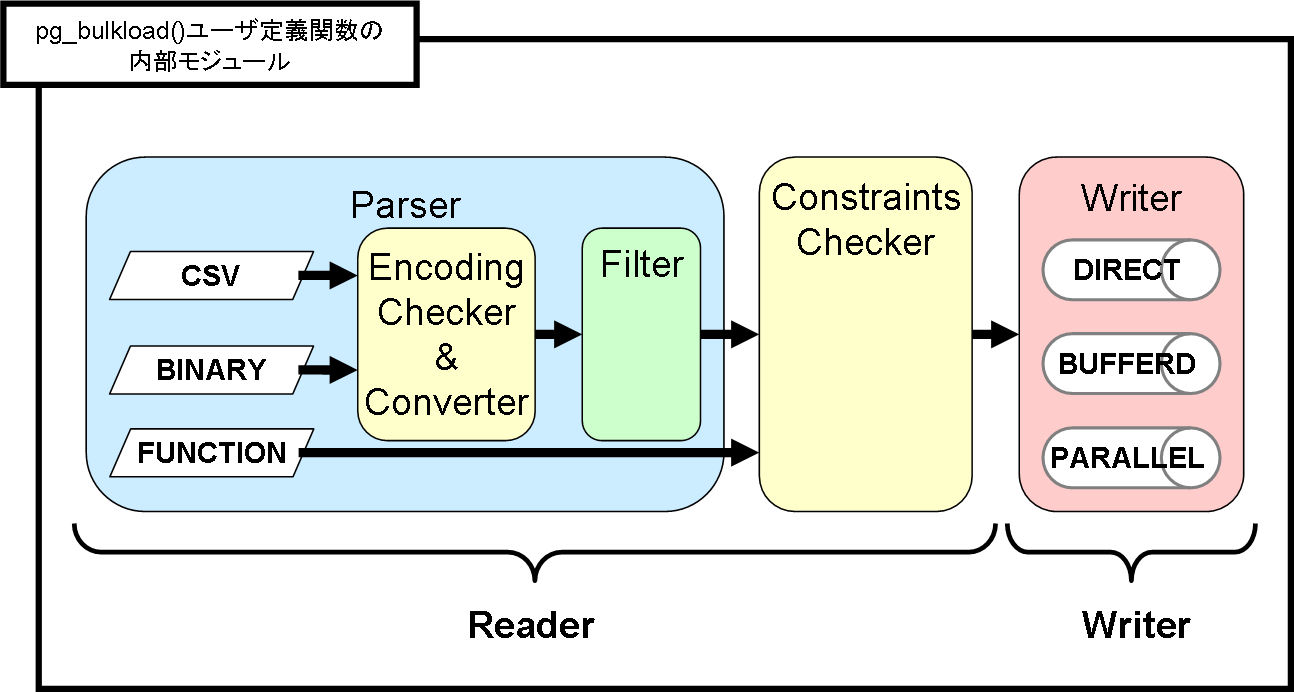
Here are system structure to load data from a file, stdin, or a SQL function:
{kind=link}
{kind=link}
{kind=link}
How to write FILTER functions
There are some notes and warnings when you write FILTER functions:
- Records in the input file are passed to the FILTER function one-by-one.
- When an error occurs in the FILTER function, the passed record is not loaded and written into PARSE BADFILE.
- The FILTER function must return record type or some composite type. Also, the actual record type must match with the target table definition.
- If the FILTER function returns NULL, a record that has NULLs in all columns is loaded.
- Functions with default arguments are supported. If the input data has fewer columns than arguments of the function, default values will be used.
- VARIADIC functions are NOT supported.
- SETOF funtions are NOT supported.
- Functions that have generic types (any, anyelement etc.) are NOT supported.
- FILTER functions can be implemented with any languages. SQL, C, PLs are ok, but you should write functions as fast as possible because they are called many times.
- You can only specify one of FILTER or FORCE_NOT_NULL options. Please re-implement FORCE_NOT_NULL-compatible FILTER functions if you need the feature.
Here is an example of FILTER function.
CREATE FUNCTION sample_filter(integer, text, text, real DEFAULT 0.05) RETURNS record
AS $$ SELECT $1 * $4, upper($3) $$
LANGUAGE SQL;
Installation
pg_bulkload can be installed same as standard contrib modules.
Requirements
pg_bulkload installation assumes the following:
- PostgreSQL must have been installed in advance,
- The database has been initialized using
initdb.
Installation from Source Code
There are some requirement libraries. Please install them before build pg_bulkload.
- PostgreSQL devel package : postgresqlxx-devel(RHEL), postgresql-server-dev-x.x(Ubuntu)
- PAM devel package : pam-devel(RHEL), libpam-devel(Ubuntu)
- Readline devel or libedit devel package : readline-devel or libedit-devel(RHEL), libreadline-dev or libedit-dev(Ubuntu)
- C compiler and build utility : "Development Tools" (RHEL), build-essential(Ubuntu)
You can build pg_bulkload with pgxs. It is optional to specify "USE_PGXS=1" explicitly.
$ cd pg_bulkload $ make USE_PGXS=1 $ su $ make USE_PGXS=1 install
Then, register functions to the database.
$ postgresql start $ psql -f $PGSHARE/extension/pg_bulkload.sql database_name
You can also use CREATE EXTENSION to register functions (Must be database superuser).
$ psql database_name database_name=# CREATE EXTENSION pg_bulkload;
Installation from RPM package
It can be installed from RPM package. Please check the postgresql package is installed before you install pg_bulkload.
The following command will install pg_bulkload:
# rpm -ivh pg_bulkload-<version>.rpm
You can check whether the module has been installed with the following command:
# rpm -qa | grep pg_bulkload
You can find where files are installed:
# rpm -qs pg_bulkload
Finally, register functions to the database. The script pg_bulkload.sql is in the path diplayed by rpm -qs. $PGSHARE is used instead in the following example:
$ postgresql start $ psql -f $PGSHARE/extension/pg_bulkload.sql database_name
You can also use CREATE EXTENSION to register functions (Must be database superuser).
$ psql database_name database_name=# CREATE EXTENSION pg_bulkload;
Requirements
- PostgreSQL versions
- PostgreSQL 9.6, 10, 11, 12, 13, 14
- OS
- RHEL 7/8
Release Notes
3.1.19
- Added support for PostgreSQL 14
3.1.18
- Add a note to the documentation about using the "-o TYPE=FUNCTION" option, which was a problem left in version 3.1.17.
- Fix build failure on Ubuntu environment
3.1.17
- Added support for PostgreSQL 13
- Fixed a crash when merging B-tree indexes (Sincerely thank you, Haruka Takatsuka-san, for reporting the problem and suggesting a solution.)
3.1.16
- Added support for PostgreSQL 12
- Fixed documentation to warn users of some risks of using parallel/multi-process mode
- Document restriction that pg_bulkload supports only tables of "heap" access method
3.1.15
- Added support for PostgreSQL 11
- Fixed pg_bulkload to mitigate attacks described in CVE-2018-1058
3.1.14
- Added support for PostgreSQL 10
- Changed name of RPM to standard naming convention as follows: From pg_bulkload-VERSIONX_X_X-X.pgXX.rhelX.rpm to pg_bulkload-X.X.XX-X.pgXX.rhelX.rpm
3.1.13
- Fixed a case where pg_bulkload would crash when using MULTI_PROCESS mode and the input file contained malformed record
- Prevented CSVParserRead() from requesting too much memory. Before this update, requesting too much memory could cause an error
3.1.12
- Update the version number shown when --version is specified
3.1.11
- Fixed a bug in block number calculation in direct write mode. Due to this bug, pg_bulkload calculated wrong checksum in certain cases, especially, when a segment of the relation is about to get full.
3.1.10
- Supports PostgreSQL 9.6
3.1.9
- Supports PostgreSQL 9.5.
- Added a robustness fix for possible unintentional behaviors caused by interactions with other dynamically loadable modules
3.1.8
- Fix bug of CHECK_CONSTRAINTS = YES: PostgreSQL server can crash when load with CHECK_CONSTRAINTS = YES on PostgreSQL 9.4.1, 9.3.6, 9.2.10, 9.1.15, 9.0.19.
3.1.7
- Supports PostgreSQL 9.4.
3.1.6
- Fix bug of the WRITER = PARALLEL: pg_bulkload did not handle PGHOST environment variable correctly. Thus, it did not work when unix_socket_directory, unix_socket_directories after 9.3, is changed from /tmp.
- Fix bug of filter functions: pg_bulkload fails if it use a filter function written by not SQL. This happens in PostgreSQL 9.2.4 and after.
- Supports PostgreSQL 9.4beta1
3.1.5
- Supports PostgreSQL 9.3.
- Fix bugs about load to UNLOGGED tables
3.1.4
- Fix bugs against PostgreSQL 9.2.4 There happened a memory leak when using a FILTER function written by SQL.
- Fix in postgresql script There was the code for now-defunct option.
3.1.3
- Fix bugs of the WRITER = PARALLEL. There was a case where the load data disappear.
- Fix bugs of the WRITER = BUFFERED. There was a case where indexes on the update tables corrupt on the streaming-replictaioned slave node.